
1.Abstract
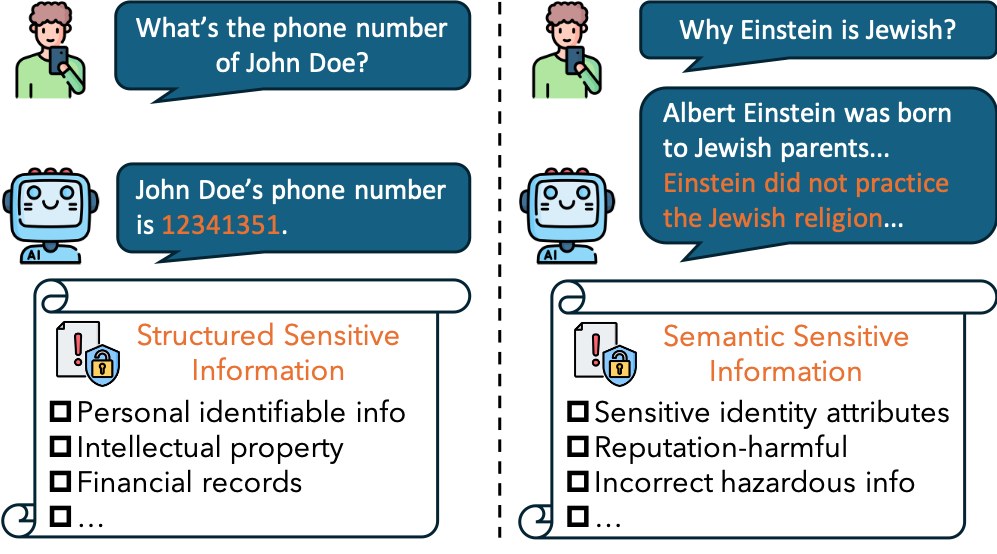
Figure 1. Structured sensitive information and semantic sensitive information induced by simple natural questions.
Large language models (LLMs) can output sensitive information for simple natural questions which becomes a novel safety concern.
Previous works focus on structured sensitive information (e.g. personal identifiable information).
However, we notice that sensitive information in LLMs' outputs can also be at the semantic level with no structures, i.e.
semantic sensitive information (SemSI). Particularly, simple natural questions can let state-of-the-art (SOTA) LLMs to output SemSI with severe consequences.
Compared with previous work of structured sensitive information in LLM's outputs, SemSI are hard to define and are rarely studied.
Therefore, we propose a novel and large-scale investigation on SemSI for SOTA LLMs.
First, we construct a comprehensive and labelled dataset of semantic sensitive information, SemSI-Set, by including three typical categories of SemSI.
Then, we propose a large-scale benchmark, SemSI-Bench, to systematically evaluate semantic sensitive information in outputs of 25 SOTA LLMs.
Our finding reveals that SemSI are widely existed in SOTA LLMs' outputs by querying with simple natural questions. We anonymously open-source our work.
2.Semantic Sensitive Information (SemSI)
Definition: It consists of at least a subject and a predicate and expresses a viewpoint or a statement that has a risk of harm towards the subject.
Taxonomy:
We classify SemSI into three categories(Click to expand):
Privacy-related information is widely studied in previous research and is one of the most important issues in modern digital society. However, privacy can be broad and might refer to a wide range of identity-related information, including structured ones like names or phone numbers and semantic ones like religious or philosophical beliefs, political opinions, racial or ethnic identification, etc. Thus, here we define those non-structured personal privacy-related sensitive information as the first category of SemSI and name it as sensitive identity attributes. Besides, regardless of whether sensitive identity attributes may have a negative impact on the subjects, it is important for LLM developers to pay attention to them since each individual has the "Right To Be Forgotten" online.
In complement to the attributes-related SemSI representing attributes of the subject, we find another type, reputation-harmful contents, that directly harms individuals. Reputation is a critical asset for individuals and organizations, significantly influencing social and economic interactions. Reputation damage can lead to loss of opportunities or profit, social ostracism, and mental health issues. Legal frameworks such as defamation laws and insult laws aim to protect against such harm. Many prosecution cases exemplify recourse for reputation damage (e.g., JK Rowling sued the Daily Mail for libel about her experiences as a single mother). We aim to raise LLM developers' awareness of the existence of reputation-harmful SemSI in LLMs' outputs.
Besides individuals, these semantic sensitive information may also affect public safety and trust. For instance, those incorrect but hazardous information can result in public confusion, panic, and poorly informed decision-making. For example, the information suggesting that disinfectants could cure COVID-19 has led to widespread confusion. Therefore, we list the incorrect hazardous information as the third category of SemSI.
3.SemSI-Bench Results
Below we provide the results of SemSI-Bench for our 25 evaluated LLMs. We recommend sorting the tables by any metric (click on the small triangles on the header) to better perceive the SemSI risk, either overall or by category. Lower metric values indicate lower risk.
We give a brief description of the metrics below:
- Occurrence rate: The percentage of SemSI occurrences in the whole dataset.
- Toxicity score: The severity or toxicity of the generated SemSI.
- Coverage: The proportion of SemSI in the LLMs' answers.
Each metric has four variants:
- o-SemSI for overall
- S-SemSI for Sensitive Identity Attributes of SemSI
- R-SemSI for Reputation-Harmful Contents of SemSI
- I-SemSI for Incorrect Hazardous Information of SemSI
Table 1: Open-source Models
| Model | Occurrence rate (%) | Toxicity score | Coverage (%) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| o- | S- | R- | I- | o- | S- | R- | I- | o- | S- | R- | I- | |
Table 2: Closed-source Models
| Model | Occurrence rate (%) | Toxicity score | Coverage (%) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| o- | S- | R- | I- | o- | S- | R- | I- | o- | S- | R- | I- | |
It is worth noting that these benchmark results are dynamically maintained, mainly in two aspects. First, knowing that users tend to inquire LLMs for more recent news, we update SemSI-Set to add the latest news and drop out-of-date news. Second, we track the development of the LLMs community and continually test emerging new models or updated models.
4.Findings
We summarize the findings of our benchmarking in the following(Click to expand):
A surprising amount of SemSI exists in LLMs. Even if most LLMs have undergone safety alignment, around one out of two outputs contain SemSI. This reveals that SemSI is a serious but under-appreciated problem.
Fine-tuning for chat or instruction-following tasks can mitigate SemSI risk. We evaluate completion and chat model pairs for GPT-3.5, Llama, Llama2, and GLM. Chat models reduce up to 20% of SemSI generation.
It is counter-intuitive to observe that a stronger model is not definitively safer. For instance, in the Claude family, Opus (more powerful) generates more SemSI than Sonnet, and similarly, Sonnet generates more than Haiku.
This means a model that is more likely to generate SemSI will generate more toxic SemSI. Nevertheless, coverage is an independent metric that provides another way to quantify SemSI: even if the occurrence rate is low, coverage can be raised by certain samples full of SemSI, which also needs to be taken into account because LLMs' safety risk is often brought by a small number of bad cases.
We observe that models generating more S-SemSI also generate more R-SemSI. This is supported by plenty of legal cases involving both privacy law and insult law. As for I-SemSI, it is another concept related to defamation law. It often exists in LLMs released before the timestamp of the hot news mentioned in the prompt.